

Introduction
I’ve been working in the data integration and data warehousing space for over 15 years; and the projects I’ve contributed to were mostly built using on premise tooling/databases. I’ve been keeping a close eye on AWS for several years; and some time ago Google Cloud, which appears to me as being the more data-focused of the big 3 public cloud providers, caught my interest.

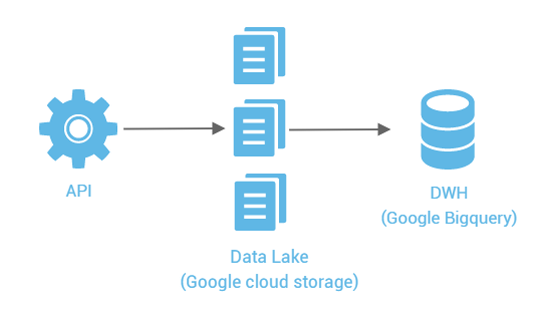
After the worst part of the pandemic was behind us, I started an internal project on Google Cloud’s data stack to gain some hands-on experience; and the goal was to build a data lake containing some climate data; like temperatures, precipitation; on Google cloud storage and a downstream data warehouse on BigQuery. Since I have a bad habit of adding minor extras to, what I think is a reasonable challenge; I chose to use a dataset which was only accessible through an API as the primary source of data. And then I invited a colleague with comparable experience to try to build something similar on AWS, and he happily accepted. We’ll zoom in on several aspects of this over the next few months; we’ll kick off with having a better look at “API’s”.
What is an ‘API’?
It stands for application programming interface; which you probably knew. It’s a set of functions that enables an application to access data and pass instructions to other software components.
Take the menu in your local restaurant as a real world example. It defines the possible instructions and values you can provide the waiter when you place your order; and as a response you get your order
The concept of using API is not the latest innovation in IT, but it’s now finding traction across many domains.
What does it offer?
It offers quite a few things, but let’s focus on the most important ones (at least to me :-))
- Security: the API offers another security layer, which defines who accesses the data, which data, when it can be accessed, effectively shielding the backend systems.
- Standardization on one technology instead of every consuming application imposing another technical requirement on the platform.
- Reducing dependencies: If any change is occurring to a system; the API needs to be altered accordingly; but all downstream systems should be unaffected.
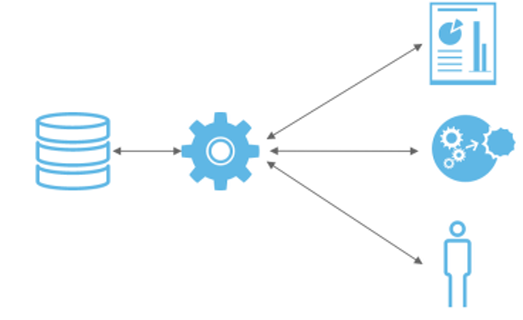
In data integration domain
As a system owner, having more control on how your system’s data is pushed/pulled is a welcome upgrade over the interfaces that have dominated the landscape for years. Reducing the dependencies of drivers, packages,… every time a system change is performed. And most of all; downstream applications can focus on delivering their own business goals with far less knowledge of the upstream systems.
Broad usage of API’s will ensure that both system and business knowledge is used effectively during design of an integration process. Some of these are double edged blades; as an example, the API we used to access the climate data imposed some limitations on how many records that could be retrieved by a single call; protecting the source system. But in turn it’s bringing some extra requirements to the downstream implementation. Within the same project/organization this kind of API functionality should be used carefully.
Next time we’ll take a better look at the data lake, we’ll take a look at the advantages and how we’ve set it up.